こんにちは、hokkyokunです。
Pythonを用いてグーグル翻訳のウェブページをスクレイピング、翻訳したテキストをCSVファイルで出力するプログラムを作りました。
プログラミング代行いたします。
Python・VBAのコード対応です。
【VBA】
エクセルの自動処理全般
【Python】
スクレイピングによる、インターネット操作の自動化
デスクトップツール(データ解析等)
ワードプレスの自動化・効率化(自動更新、記事新規作成等の自動化)
ココナラで依頼を受けておりますので、お気軽にご相談ください。
価格もプログラミングスクールに通うよりは安価で、書籍を買うよりは高い場合もありますが、動画で見ることができるので、書籍よりも学習効率が上がります。
Python関連の書籍を出していて、めちゃくちゃ売れている酒井 潤さんの動画もあります。
【汎用性抜群】一つのテキストデータを翻訳するコード
工程確認
コードを作成する前に、やりたいプログラムを整理します。
先ずは、単純かつ汎用性のあるプログラムとして、
「一つの翻訳したいテキストを引数として、翻訳後のテキストを戻り値として吐き出させます」
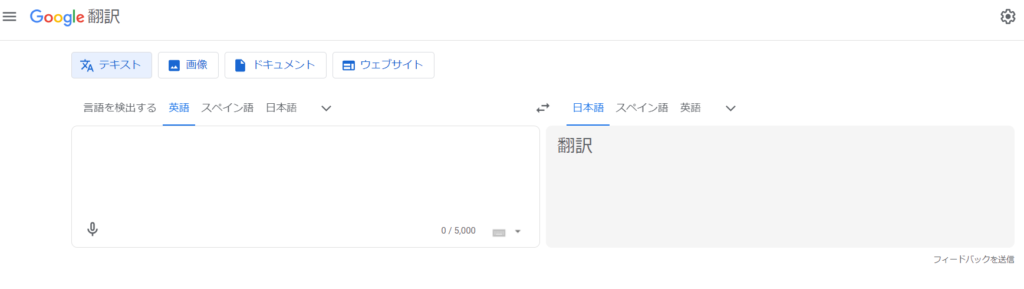
- グーグルの翻訳ページにアクセス
- 翻訳前テキストを(ページ左側の)テキストボックスに入力
- 時間を置き、翻訳されたテキストを取得する
すごく単純ですが、これを作り終えた後、複数のテキストデータを翻訳するプログラムを考えていきます。
コード
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
def translate_single_by_google(soruce_text):
#グーグル翻訳ページにアクセス
url = "https://translate.google.co.jp/?hl=ja"
driver = webdriver.Chrome()
driver.get(url)
#翻訳前データを入力
input_text = driver.find_element(By.CLASS_NAME,"er8xn")
input_text.send_keys(soruce_text)
#時間を置く、これがないとグーグルが翻訳する前に、翻訳語テキストを取得することになる。
#また、相手サーバーへの負荷を抑えるためのマナー
time.sleep(5)
#翻訳されたデータを取得
output_texts=driver.find_elements(By.CLASS_NAME,"ryNqvb")
result=""
for output_text in output_texts:
result+=output_text.text
print(result)
return result実用
実際に使ってみます。
source_text = "hello world"
result=translate_single_by_google(soruce_text=source_text)
「hello world」を翻訳してみました。
「こんにちは世界」と日本語訳出来ました。
複数のテキストデータを翻訳
工程
次に複数のデータを一気にやってみましょう。
ただし、このプログラムは待ち時間を設定するため非常に時間がかかります。
なので、いつ止めてもいいように、翻訳したテキストは随時、csvに出力するようにします。
- 翻訳したいデータをデータフレームで取得
- こちらのグーグル翻訳ページにアクセス
- ここから繰り返し処理
- 翻訳前テキストを取得
- 翻訳前テキストを左側のテキストボックスに入力する
- 時間を置き、翻訳されたテキストを取得する
- ②のテキストボックスをクリアする
- 翻訳されたテキストをデータフレームに入力し、csvに吐き出す
- ①に戻る
前処理として、csvファイルを用意します。
最初の行に「翻訳前,翻訳後」と入力し、
改行して訳したい英語を入力していきます。

ファイルを作ったらファイルパスを指定して、引数として持たせるようにします。
コード
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import pandas as pd
def translate_multiple_by_google(file_path):
#翻訳するデータを読み取り
#エンコーディングは保存しているcsvに応じて変更してください
df = pd.read_csv(file_path,encoding="utf-8-sig")
#グーグル翻訳ページにアクセス
url = "https://translate.google.co.jp/?hl=ja"
driver = webdriver.Chrome()
driver.get(url)
#翻訳前データ分、複数処理
for index,row in df.iterrows():
#翻訳前データを入力
input_text = driver.find_element(By.CLASS_NAME,"er8xn")
input_text.send_keys(row["翻訳前"])
#時間を置く、これがないとグーグルが翻訳する前に、翻訳語テキストを取得することになる。
#また、相手サーバーへの負荷を抑えるためのマナー
time.sleep(5)
#翻訳されたデータを取得
output_texts=driver.find_elements(By.CLASS_NAME,"ryNqvb")
result=""
for output_text in output_texts:
result+=output_text.text
print(result)
#翻訳前のデータを入力したテキストボックスをクリア。
input_text.clear()
#翻訳後のデータをデータフレームに入力
df.at[index,"翻訳後"] = result
#ひとつ翻訳されるたびにデータを出力
df.to_csv("result.csv",encoding="utf-8-sig",index=False)
#次の処理に移る前の待ち時間(おそらくなくても大丈夫だが念のため)
time.sleep(1)上記でも触れましたが、引数としてあらかじめ作成したcsvファイルを持たせます。
これは今から翻訳するためのテキストデータです。
エンコーディングは日本語にしても文字化けしない「utf-8-sig」をよく使うのでそうしていますが、utf-8でもいいですし、shift-jisでもいいので、適切に変更してください
実行
実行してみます。
source_file = "source_texts.csv"
translate_multiple_by_google(file_path=source_file)実行前
翻訳前の「source_texts.csv」はこんな感じです。
実行後
翻訳をした「result.csv」はこのようになります。

Python学習ではUdemyがおすすめです。
値段も手ごろで動画で学習できるので書籍よりもわかりやすいです。
もし、Pythonの学習を本格的に進めるのであれば、PyQもおすすめです。

機械学習や統計分析、Webアプリなどの実務的な使い方の学習カルキュラムも充実しています。
こちらもサブスク費用でして、月額3,040円のライトプラント月額8,130円のスタンダードプランがあります。
おすすめはスタンダードプランです。現役エンジニアへの質問が可能です。
本格的な学習を進めるとどうしても詰まるところが出てくるので、誰かに相談できる環境があるのとないのとでは、学習速度に大きな差が出てきます。
また、プログラムの作成を代行しています。
ではでは。









